
Amazon Textract is AWS’s machine finding out service that reads and processes paperwork mechanically. It does further than merely flip images into textual content material like major OCR devices. It is best to put it to use to tug information from varieties and tables, course of every typed and handwritten textual content material, work with PDFs and scanned images, and take care of paperwork in numerous languages. It even comes with ready-to-use devices for explicit paperwork like invoices, IDs, and lending paperwork.
Our analysis of real-world implementations reveals Textract’s clear strengths and limitations. It excels at processing structured financial paperwork and varieties all through the AWS ecosystem. The pricing begins at $1.50 per 1,000 pages for major textual content material extraction, scaling up for specialised doc types like invoices or lending paperwork.
Nevertheless, the evaluation moreover revealed that the platform falls transient almost about:
➡️
1. Accuracy when processing handwritten textual content material
2. Costs that scale poorly for large volumes
3. Difficult doc layouts and non-standard formatting
4. Desk extraction with superior formatting
5. Setup requiring AWS expertise and ongoing repairs
Allow us to check out the very best Textract choices that may make it easier to select the becoming system in your doc processing needs.
At Nanonets, we course of tens of thousands and thousands of paperwork month-to-month for over 500 enterprises, along with 35% of Fortune 500 companies. This offers us distinctive insights into what works (and what doesn’t) in doc processing. We now have seen firsthand how corporations wrestle to hunt out the becoming doc processing decision, notably when evaluating Amazon Textract choices.
For the goal of this comparability, we evaluated Textract choices primarily based totally on:
- Precise effectivity information from processing tens of thousands and thousands of paperwork
- Direct recommendations from enterprise purchasers who switched platforms
- Unbiased client evaluations from G2, Capterra, Gartner, and TrustRadius
- Fingers-on testing by our doc processing consultants
| Sr No. | Product | Predominant attribute | G2 rating | Free trial | Pricing | Complete ranking* |
|---|---|---|---|---|---|---|
| 1 | Amazon Textract | AWS-native doc processing | 4.4/5 | No | Pay-as-you-go ($1.50 per 1,000 pages) | 43.4 |
| 2 | Nanonets | End-to-end automation with 98% accuracy | 4.8/5 | Certain (500 pages) | Pay-as-you-go, First 500 pages free | 46.5 |
| 3 | Rossum | Cognitive information seize | 4.4/5 | No | Personalized pricing | 43.8 |
| 4 | Docparser | Rule-based extraction | 4.6/5 | Certain | Begins at $39/month | 44.0 |
| 5 | Azure DI | Enterprise integration | 4.5/5 | Certain | Pay-as-you-go | 43.2 |
| 6 | Google Cloud Doc AI | ML-powered processing | 4.2/5 | Certain | Pay-as-you-go | 43.2 |
| 7 | ABBYY FlexiCapture | Superior OCR capabilities | 4.1/5 | No | Begins at $4,150 (one-time) | 44.3 |
| 8 | Tungsten Seize | Extreme-volume doc scanning | 4.3/5 | Certain | Personalized pricing | 43.0 |
| 9 | Laserfiche | Enterprise content material materials administration | 4.7/5 | Certain | Begins at $50/client/12 months | 43.9 |
| 10 | Hyperscience | Human-in-loop workflows | 4.6/5 | No | Personalized pricing | 46.3 |
(*Talk about with scoring methodology on the bottom)
Now, let’s research each totally different intimately to understand their explicit strengths, limitations, and supreme use cases. We’ll analyze how they consider to Textract and present you methods to resolve which decision best suits your doc processing needs.
1. Nanonets
Nanonets is an AI-powered document processing platform that goes previous major OCR to provide end-to-end automation. In distinction to Textract’s template-based methodology, we use deep finding out to understand doc context and adapt to new layouts mechanically. Our platform combines OCR, pure language processing, and machine finding out to take care of all of the issues from information extraction to workflow automation.
💡
Key choices:
1. Intelligent doc classification and routing
2. Automated information validation and error checking
3. Personalized model teaching with as few as 10 samples
4. Pre-built fashions for invoices, receipts, IDs
5. Multi-stage approval workflows
6. Database matching for information verification
7. Automated export to accounting methods
8. Webhook and API integrations
9. Constructed-in human verification devices
| Professionals of Nanonets | Cons of Nanonets |
|---|---|
| Template-free processing with self-learning fashions | Better worth for low volumes |
| Helps 40+ languages | Preliminary model teaching requires time |
| Pre-trained fashions for frequent paperwork | Finding out curve for superior workflows |
| In depth integration capabilities | UI is likely to be overwhelming at first |
| Sturdy workflow automation capabilities | |
| Constructed-in verification and approval flows | |
| Sturdy API documentation and help | |
| Widespread model enhancements from corrections |
Pricing: Free tier obtainable for first 500 pages. Skilled plan begins at $999/month for 10,000 pages.
Biggest fitted to: Mid to large organizations in finance, healthcare, logistics, and manufacturing sectors processing totally different doc types.
How does Nanonets consider to Amazon Textract?
|
Parameter |
Nanonets |
Amazon Textract |
|---|---|---|
|
Ease of Use |
9.3 |
8.9 |
|
Ease of Setup |
9.1 |
8.9 |
|
Prime quality of Assist |
9.4 |
8.6 |
|
Meets Requirements |
9.1 |
8.8 |
|
Product Route (% constructive) |
9.6 |
8.2 |
➡️
Our take: Choose Nanonet once you’re in quest of self-learning fashions, in depth workflow automation, and built-in verification devices to automate your doc processing workflow end-to-end. Nanonets may make it easier to take care of totally different doc layouts and numerous languages or assure seamless information circulation collectively along with your current enterprise methods.
2. Rossum
{kind=link}
Rossum’s methodology to doc processing consists of using cognitive information seize as a substitute of standard template-based extraction. The platform combines AI-powered understanding with in depth workflow automation to take care of your full doc lifecycle – from receiving to processing to integration with enterprise methods.
💡
Key choices:
1. Cognitive information seize with out templates
2. Multi-channel doc receiving
3. Constructed-in exception coping with workflow
4. In depth validation pointers engine
5. Enterprise-grade integrations
6. Personalized topic validation
7. ISO 27001 and SOC 2 licensed
8. Two-way communication for exceptions
| Professionals of Rossum | Cons of Rossum |
|---|---|
| No templates wished for model spanking new layouts | Better worth for low volumes |
| Greater coping with of superior paperwork | System glitches all through updates |
| Sturdy enterprise-grade help | Slower processing of big PDFs |
| Constructed-in exception administration | Steeper finding out curve initially |
| In depth validation capabilities | Difficult API for tax constructions |
| Widespread AI enhancements | Restricted Excel help |
| Versatile customization selections | |
| Sturdy security compliance |
Pricing: Enterprise-focused pricing with custom-made quotes primarily based totally on amount. Consists of SLA ensures and devoted help.
Biggest fitted to: Organizations all through manufacturing, retail, and financial corporations that need full doc automation. Rossum considerably excels in AP departments and shared service amenities processing totally different vendor paperwork.
How does Rossum consider to Amazon Textract?
|
Parameter |
Rossum |
Amazon Textract |
|---|---|---|
|
Ease of Use |
8.5 |
8.9 |
|
Ease of Setup |
8.0 |
8.9 |
|
Prime quality of Assist |
9.2 |
8.6 |
|
Meets Requirements |
8.3 |
8.8 |
|
Product Route (% constructive) |
9.8 |
8.2 |
➡️
Our take: Choose Rossum if it’s worthwhile to course of various doc types with sturdy validation and compliance controls. The platform considerably shines in accounts payable automation and vendor doc processing the place template repairs might be impractical.
3. Docparser
Docparser presents a rule-based methodology using zonal OCR experience. Whereas Textract makes use of machine finding out to understand paperwork, Docparser lets you define exactly how and the place to extract information using customizable parsing pointers.
💡
Key choices:
1. Customizable zonal OCR extraction
2. Superior desk parsing capabilities
3. Wise doc routing system
4. Pre-built parsing templates
5. Automated information formatting
6. Multi-format doc help
7. In depth API entry
| Professionals of Docparser | Cons of Docparser |
|---|---|
| Further precise extraction administration | Requires information rule setup |
| Greater with fixed layouts | Restricted AI capabilities |
| Stronger desk extraction | Finding out curve for setup |
| Further cheap for low volumes | One language at a time |
| Easier integration selections | Template repairs wished |
| Quick processing tempo | Not final for numerous layouts |
| Wonderful purchaser help | |
| Clear pricing development |
Pricing: Clear tiered pricing starting at $39/month for 100 paperwork. Advertising and marketing technique at $159/month for 1,000 paperwork. Enterprise plans obtainable.
Biggest fitted to: Small to mid-sized corporations processing fixed doc codecs, notably in finance and operations.
How does Docparser consider to Amazon Textract?
|
Parameter |
Docparser |
Amazon Textract |
|---|---|---|
|
Ease of Use |
9.0 |
8.9 |
|
Ease of Setup |
8.8 |
8.9 |
|
Prime quality of Assist |
8.9 |
8.6 |
|
Meets Requirements |
8.7 |
8.8 |
|
Product Route (% constructive) |
8.5 |
8.2 |
➡️
Our take: Choose Docparser once you need granular administration over extraction pointers and work primarily with structured paperwork. Its rule-based methodology makes it final for automated workflows the place paperwork have predictable codecs and in addition you need precise desk extraction. The platform presents increased price for smaller doc volumes and gives further simple integration selections.
4. Azure AI Doc Intelligence
{kind=link}
Azure AI Document Intelligence is part of Microsoft’s cloud platform, Azure, which gives over 200 cloud corporations for corporations. It represents Microsoft’s enterprise-focused methodology to doc processing, offering processing capabilities that run every throughout the cloud and by your self servers. You’ll be capable to deploy it by the use of containers that suit your explicit information storage and processing location requirements.
💡
Key choices:
1. Widespread doc analysis (be taught/construction)
2. Pre-built enterprise doc fashions
3. Personalized neural model teaching
4. Doc classification
5. Container-based deployment
6. Azure service integration
7. Constructed-in validation pointers
8. Multi-language help
9. Human overview workflows
| Professionals of Azure DI | Cons of Azure DI |
|---|---|
| On-premises deployment risk | Difficult preliminary configuration |
| Pre-built enterprise fashions | Requires technical expertise |
| Sturdy Azure integration | Finding out curve for superior choices |
| Personalized neural fashions | Updates may trigger disruptions |
| Doc classification | Worth administration complexity |
| Container help | Documentation gaps |
| Enterprise security | |
| Plenty of deployment picks |
Pricing: Pay-as-you-go primarily based totally on pages processed. Free tier consists of 500 pages month-to-month. Enterprise pricing obtainable for prime volumes.
Biggest fitted to: Enterprises all through healthcare, finance, and authorities sectors that must course of paperwork throughout the cloud and on their servers.
How does Azure Type Recognizer consider to Amazon Textract?
|
Parameter |
Azure DI |
Amazon Textract |
|---|---|---|
|
Ease of Use |
8.5 |
8.9 |
|
Ease of Setup |
8.0 |
8.9 |
|
Prime quality of Assist |
8.5 |
8.6 |
|
Meets Requirements |
9.0 |
8.8 |
|
Product Route (% constructive) |
9.2 |
8.2 |
➡️
Our take: Choose Azure Doc Intelligence everytime you need further administration over the place your doc processing happens. It may even be a good choice once you already use Microsoft corporations.
5. Google Cloud Doc AI
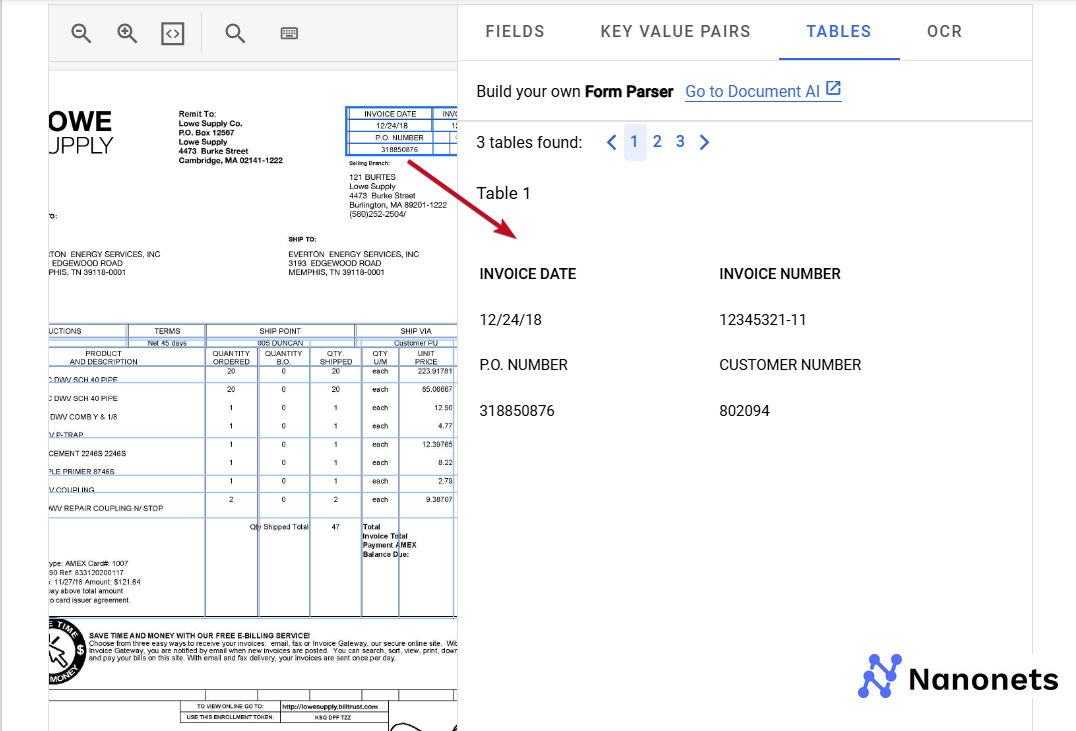
Document AI represents Google’s enterprise methodology to doc processing. Part of the company’s cloud division, it combines OCR, pure language processing, and machine finding out to remodel unstructured paperwork into actionable information. It gives an end-to-end platform for doc processing, analysis, and storage.
💡
Key choices:
1. Widespread doc processors (OCR, splitter, parser)
2. Pre-built enterprise processors
3. Doc AI Workbench for custom-made fashions
4. Doc AI Warehouse for storage
5. Human-in-loop overview capabilities
6. Constructed-in processing console
7. Multi-language help
8. Batch processing limitations
9. API-first construction
| Professionals of Doc AI | Cons of Doc AI |
|---|---|
| In depth pre-built processors | Restricted batch processing |
| Sturdy ML/AI capabilities | Difficult pricing development |
| Constructed-in storage decision | Requires technical expertise |
| Human overview workflows | Better finding out curve |
| Google Cloud integration | Enterprise-focused pricing |
| Widespread model enhancements | Documentation gaps |
| Sturdy OCR accuracy | |
| Versatile deployment |
Pricing: Pay-as-you-go primarily based totally on doc processing amount. Free tier obtainable for testing. Enterprise pricing obtainable for prime volumes.
Biggest fitted to: Enterprises processing totally different doc types at scale, notably those that require superior analysis. If an integration with Google Cloud is smart to your enterprise.
How does Google Cloud Doc AI consider to Amazon Textract?
|
Parameter |
Google Cloud Doc AI |
Amazon Textract |
|---|---|---|
|
Ease of Use |
8.7 |
8.9 |
|
Ease of Setup |
8.5 |
8.9 |
|
Prime quality of Assist |
8.0 |
8.6 |
|
Meets Requirements |
8.8 |
8.8 |
|
Product Route (% constructive) |
9.2 |
8.2 |
➡️
6. ABBYY FlexiCapture
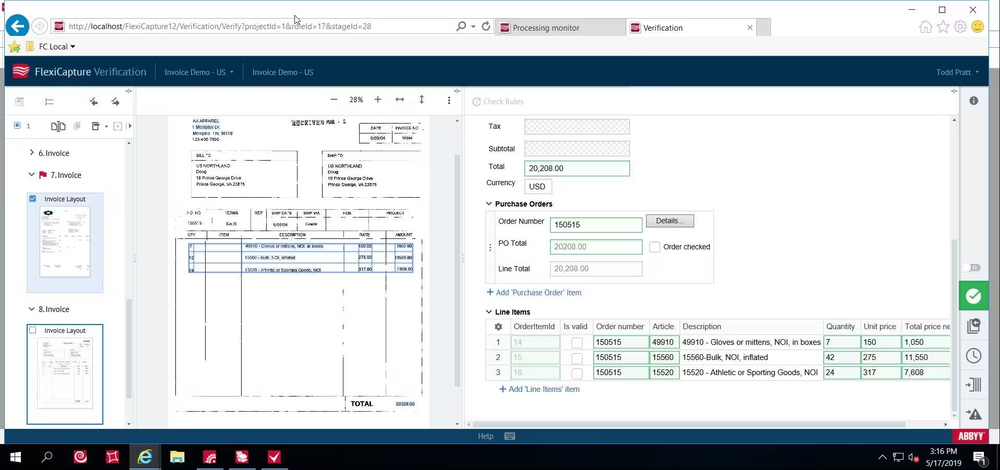
ABBYY FlexiCapture is a sturdy intelligent doc processing platform that automates the seize, classification, and information extraction from every kind of doc types and codecs. In distinction to Textract’s cloud-only model, FlexiCapture presents every on-premises and cloud deployment selections, making it acceptable for organizations with strict information security and compliance requirements.
💡
Key choices:
1. Superior OCR for structured and unstructured paperwork
2. AI-based information seize and extraction
3. Intelligent doc classification and separation
4. Scalable batch processing for prime volumes
5. Customizable enterprise pointers and validation
6. Multi-channel enter (scanner, e-mail, fax, cell)
7. Seamless integration with BPM, RPA, and ECM methods
8. Versatile deployment selections (on-premises, cloud, hybrid)
9. Multi-language help
| Professionals of FlexiCapture | Cons of FlexiCapture |
|---|---|
| Extraordinarily right information extraction | Difficult setup and configuration |
| Handles numerous doc codecs | Steep finding out curve |
| Scalable for high-volume processing | Better upfront funding |
| Sturdy integration capabilities | Requires specialised IT talents to care for |
| Versatile deployment selections | |
| Sturdy compliance and security options |
Pricing: Primarily based totally on the number of pages processed yearly, with the related charge per internet web page decreasing as amount will improve. On-premises and cloud-based pricing fashions might be discovered, with on-premises requiring a greater upfront funding nonetheless lower ongoing costs. Precise pricing shouldn’t be publicly disclosed.
Biggest fitted to: Enterprises and organizations with high-volume doc processing needs and strict compliance requirements, like healthcare, finance, and authorities.
How does ABBYY FlexiCapture consider to Amazon Textract?
|
Parameter |
ABBYY FlexiCapture |
Amazon Textract |
|---|---|---|
|
Ease of Use |
8.8 |
8.9 |
|
Ease of Setup |
8.0 |
8.9 |
|
Prime quality of Assist |
8.5 |
8.6 |
|
Meets Requirements |
9.0 |
8.8 |
|
Product Route (% constructive) |
10.0 |
8.2 |
➡️
7. Tungsten Seize (beforehand Kofax Seize)
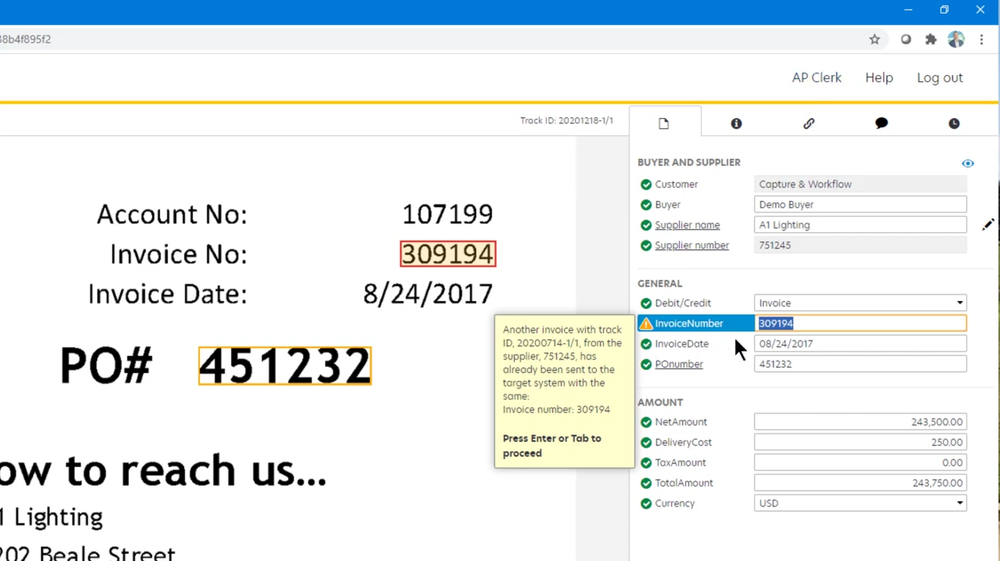
Tungsten Capture is a doc scanning and information extraction decision that automates the conversion of paper paperwork into digital information. It focuses on high-volume doc scanning, OCR, and information seize.
💡
Key choices:
1. Superior doc scanning and movie processing
2. Intelligent doc separation and classification
3. Automated information extraction using OCR and ICR
4. VRS (VirtualReScan) experience for image enhancement
5. Integration with totally different Tungsten Modules for superior information extraction
6. Assist for a wide range of scanners and multi-function devices
7. Scalable construction for high-volume processing
8. Batch processing and workflow automation capabilities
9. Centralized administration and monitoring
| Professionals of Tungsten Seize | Cons of Tungsten Seize |
|---|---|
| Extraordinarily right OCR and information extraction | Difficult setup and configuration |
| Handles numerous doc types and codecs | Steep finding out curve |
| Extremely efficient image enhancement with VRS | Better upfront costs |
| Scalable for high-volume processing | Requires on-premises infrastructure |
| In depth customization selections | Restricted out-of-the-box integrations |
| Mature and confirmed experience | Older client interface design |
Pricing: Pricing depends on the number of pages scanned yearly, with amount reductions obtainable. Additional costs would possibly apply for add-on modules, expert corporations, and maintenance. Precise pricing shouldn’t be publicly disclosed, however it absolutely generally features a large upfront funding and ongoing repairs fees.
Biggest fitted to: Organizations with high-volume, centralized doc scanning requirements, similar to shared service amenities, BPOs, and large enterprises with devoted scanning departments.
How does Tungsten Seize consider to Amazon Textract?
|
Parameter |
Tungsten Seize |
Amazon Textract |
|---|---|---|
|
Ease of Use |
8.5 |
8.9 |
|
Ease of Setup |
8.0 |
8.9 |
|
Prime quality of Assist |
8.7 |
8.6 |
|
Meets Requirements |
8.8 |
8.8 |
|
Product Route (% constructive) |
9.0 |
8.2 |
➡️
8. Laserfiche
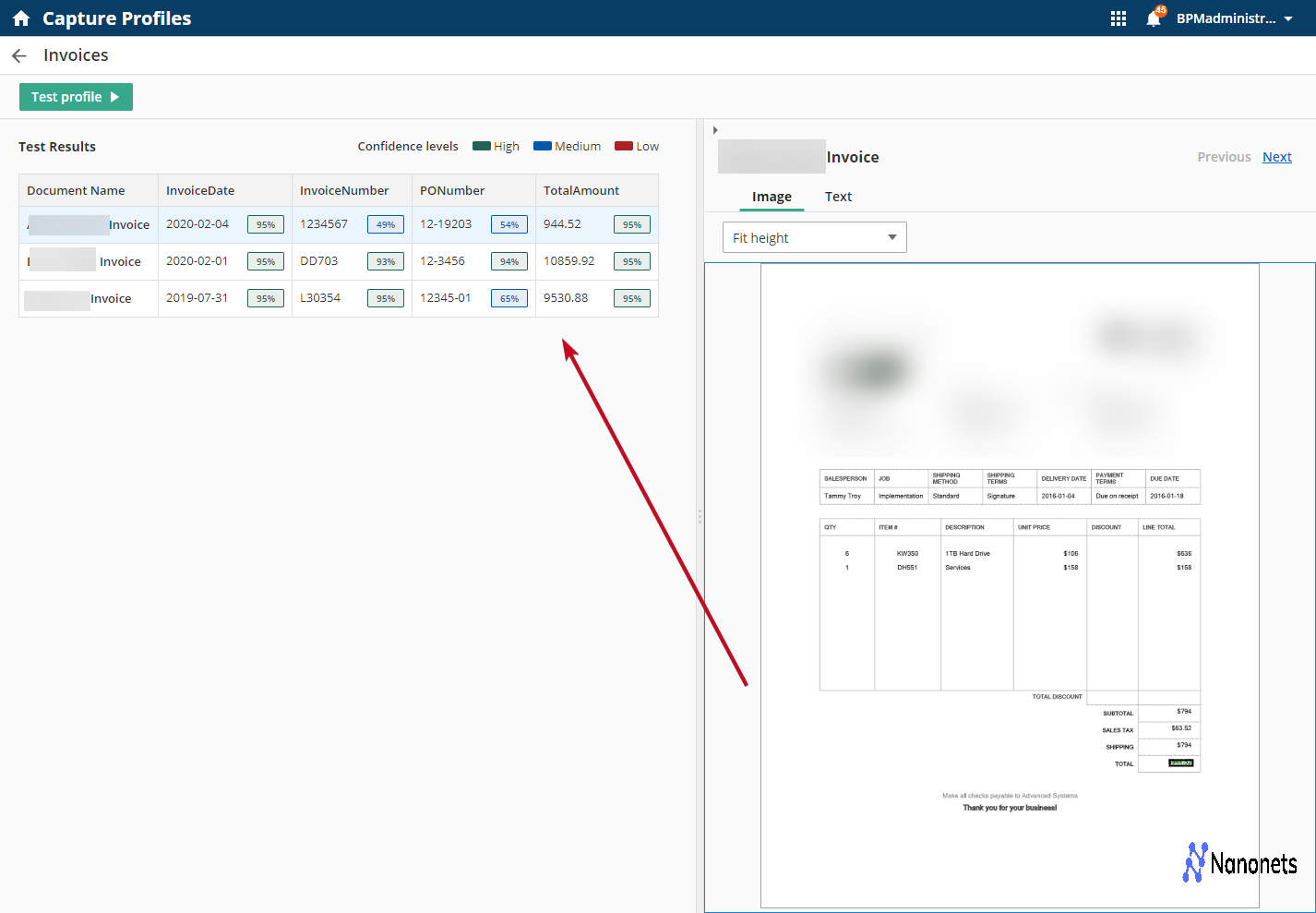
Laserfiche is a whole enterprise content material materials administration (ECM) and enterprise course of automation platform that options sturdy doc seize and processing capabilities. It presents an end-to-end decision that mixes intelligent doc seize, protected storage, workflow automation, and data administration.
💡
Key choices:
1. Intelligent doc seize and classification
2. Workflow designer for course of automation
3. Digital varieties and digital signatures
4. Doc administration and mannequin administration
5. Info administration and retention insurance coverage insurance policies
6. Secure doc storage and entry administration
7. Mobile doc seize and entry
8. Different integration selections and APIs
| Professionals | Cons |
|---|---|
| Full content material materials administration | Better upfront costs |
| Extremely efficient workflow automation | Steeper finding out curve |
| Sturdy security and compliance | Requires IT belongings to implement and protect |
| Extraordinarily customizable and extensible | Would possibly require expert corporations for superior implementations |
| Scalable for enterprise deployments | |
| Deep integration with enterprise methods |
Pricing: Gives every on-premises and cloud-based deployment selections, with pricing primarily based totally on the number of prospects and explicit modules required. You’re going to get a free trial for its cloud-based decision.
Biggest fitted to: Organizations all through industries, considerably these with superior doc administration and compliance requirements, similar to authorities companies, tutorial institutions, financial corporations corporations, and healthcare suppliers.
How does Laserfiche consider to Amazon Textract?
|
Parameter |
Laserfiche |
Amazon Textract |
|---|---|---|
|
Ease of Use |
8.8 |
8.9 |
|
Ease of Setup |
8.0 |
8.9 |
|
Prime quality of Assist |
8.9 |
8.6 |
|
Meets Requirements |
9.0 |
8.8 |
|
Product Route (% constructive) |
9.2 |
8.2 |
➡️
Our take: Choose Laserfiche once you need a full decision that mixes doc processing with doc administration, workflow automation, and data administration. It’s considerably treasured everytime you need sturdy security, compliance, and auditing capabilities alongside doc seize.
9. Hyperscience
Hyperscience is an intelligent doc processing platform that mixes AI, ML, and human-in-the-loop workflows to automate information extraction, classification, and validation. It presents an end-to-end decision that handles superior, variable, and low-quality paperwork with extreme accuracy and automation fees.
💡
Key choices:
1. AI-powered information extraction and classification
2. Assist for structured, semi-structured, and unstructured paperwork
3. ICR for handwritten textual content material and low-quality images
4. Human-in-the-loop workflows for exception coping with and validation
5. Customizable workflows and integration with current methods
6. Regular finding out and model enchancment
7. Secure and compliant infrastructure
| Professionals of Hyperscience | Cons of Hyperscience |
|---|---|
| Extreme accuracy and automation fees | Better worth as compared with standalone choices |
| Handles superior, variable, and low-quality paperwork | Longer preliminary setup and configuration |
| Human-in-the-loop workflows for exception coping with | Would possibly require important teaching information for custom-made fashions |
| Integration with enterprise methods | |
| Regular finding out and enchancment | |
| Devoted purchaser success workforce and help |
Pricing: Gives custom-made pricing.
Biggest fitted to: Enterprises with superior, high-volume doc processing needs, considerably these dealing with variable, unstructured, or low-quality paperwork. Industries similar to financial corporations, insurance coverage protection, healthcare, and authorities may probably automate claims processing, account opening, and invoice processing, with extreme accuracy and effectivity.
How does Hyperscience consider to Amazon Textract?
|
Parameter |
Hyperscience |
Amazon Textract |
|---|---|---|
|
Ease of Use |
9.3 |
8.9 |
|
Ease of Setup |
9.0 |
8.9 |
|
Prime quality of Assist |
9.1 |
8.6 |
|
Meets Requirements |
9.1 |
8.8 |
|
Product Route (% constructive) |
9.8 |
8.2 |
➡️
When you occur to’re considering shifting away from Amazon Textract, your various will rely on numerous key parts now we have acknowledged from analyzing tons of of client experiences and implementation cases.
Scoring methodology*
We now have evaluated each totally different all through 5 key parameters that matter most to organizations switching from Textract:
- Ease of use: How quickly teams can start using the system with out in depth AWS expertise
- Ease of setup: Implementation effort, notably as compared with Textract’s AWS-centric setup
- Prime quality of help: Availability and responsiveness of help, a typical ache degree with Textract
- Meets requirements: Potential to take care of doc processing needs previous Textract’s capabilities
- Product route: Regular enchancment and have development tempo
| Product | Ease of Use | Ease of Setup | Prime quality of Assist | Meets Requirements | Product Route | Complete Ranking |
|---|---|---|---|---|---|---|
| Amazon Textract | 8.9 | 8.9 | 8.6 | 8.8 | 8.2 | 43.4 |
| Nanonets | 9.3 | 9.1 | 9.4 | 9.1 | 9.6 | 46.5 |
| Rossum | 8.5 | 8.0 | 9.2 | 8.3 | 9.8 | 43.8 |
| Docparser | 9.0 | 8.8 | 8.9 | 8.7 | 8.5 | 44.0 |
| Azure DI | 8.5 | 8.0 | 8.5 | 9.0 | 9.2 | 43.2 |
| Google Cloud Doc AI | 8.7 | 8.5 | 8.0 | 8.8 | 9.2 | 43.2 |
| ABBYY FlexiCapture | 8.8 | 8.0 | 8.5 | 9.0 | 10.0 | 44.3 |
| Tungsten Seize | 8.5 | 8.0 | 8.7 | 8.8 | 9.0 | 43.0 |
| Laserfiche | 8.8 | 8.0 | 8.9 | 9.0 | 9.2 | 43.9 |
| Hyperscience | 9.3 | 9.0 | 9.1 | 9.1 | 9.8 | 46.3 |
Key selection parts
Primarily based totally on frequent challenges organizations face with Textract, ponder these factors:
Doc complexity requirements
- Would you like increased handwriting recognition than Textract presents?
- Are you processing superior tables or varieties?
- Do it’s worthwhile to take care of numerous languages efficiently?
AWS dependency points
- How tightly built-in are you with AWS corporations?
- Would a cloud-agnostic decision present further flexibility?
- Would you like on-premises deployment selections?
Worth development preferences
- Is Textract’s per-page pricing model working in your amount?
- Would you like further predictable pricing?
- What’s your month-to-month doc processing amount?
Integration needs
- Previous AWS corporations, what methods wish to connect?
- Would you like pre-built connectors to frequent enterprise devices?
- How important is API flexibility?
Automation requirements
- Would you like workflow automation capabilities?
- Is batch processing important in your use case?
- Do you require human-in-the-loop choices?
💡
– Perform items and capabilities may need modified
– Pricing fashions might differ from what’s listed
– Effectivity metrics would possibly differ primarily based in your explicit use case
– Integration selections may need expanded
– New choices may need been added
We advocate reaching out to distributors instantly for basically essentially the most current information and testing any decision fully collectively along with your exact paperwork sooner than making a selection.
Whereas enterprise choices present full choices and help, organizations with technical belongings or financial constrainst may ponder open-source choices for doc processing.
Tesseract OCR, maintained by Google, is doubtless one of the established open-source OCR engines obtainable. One other selection is EasyOCR, which presents a Python library for OCR with help for handwriting recognition and numerous languages.
Nonetheless, in distinction to the enterprise choices talked about above, open-source choices generally require important technical expertise to implement and protect and often need further development work to match choices like kind topic extraction, desk analysis, and workflow automation that come commonplace with enterprise platforms.
FAQs
What’s the excellence between ABBYY and Textract?
ABBYY FlexiCapture is a whole doc processing platform that options superior OCR, workflow automation, and enterprise integration capabilities. It presents every cloud and on-premises deployment selections. Amazon Textract, as in contrast, is a cloud-only service centered notably on information extraction and doc analysis, built-in with AWS corporations.
What’s the excellence between OCR and Textract?
OCR (Optical Character Recognition) is a experience that converts images of textual content material into machine-readable textual content material. Amazon Textract goes previous major OCR via using machine finding out to not solely acknowledge textual content material however moreover understand doc development, extract kind fields, and analyze tables mechanically. Whereas OCR merely converts textual content material, Textract gives structured information output and understanding of doc relationships.
Amazon Textract is a machine finding out service that mechanically extracts textual content material, handwriting, and information from scanned paperwork. It is part of AWS’s AI corporations, designed to course of paperwork at scale with out information intervention. The service can set up and extract information from varieties and tables whereas sustaining the distinctive doc’s development and relationships.
Can Textract extract images?
Textract processes images to extract textual content material and information from them, however it absolutely doesn’t extract images themselves. It may probably analyze images containing paperwork, varieties, tables, and handwritten textual content material, nonetheless its operate is to extract textual information and information barely than image content material materials.